
前回の記事でDockerの基本概念やコマンドを学びました。
今回は「そもそも、なぜDockerを使う意味があるのか?」について解説します。
Kubernetesはまだ先です。でも地道にいきましょう。結果的に早道です。
でもDockerのメリットを説明する前に、まずは「仮想化」そのものの話をしないと腹落ちしないと思うので、ちょっと長くなります。前半・後半にわけてみました。
Dockerのおさらい
必ず前回の記事を一通り読んでください。

前回の記事では「docker run」を使用して、Dockerの動作を一通り確認しました。
- コンテナの素(種)となる「イメージ」を取得
- 「イメージ」から「コンテナ」を生成
でしたね。
図にすると、こんな感じ。
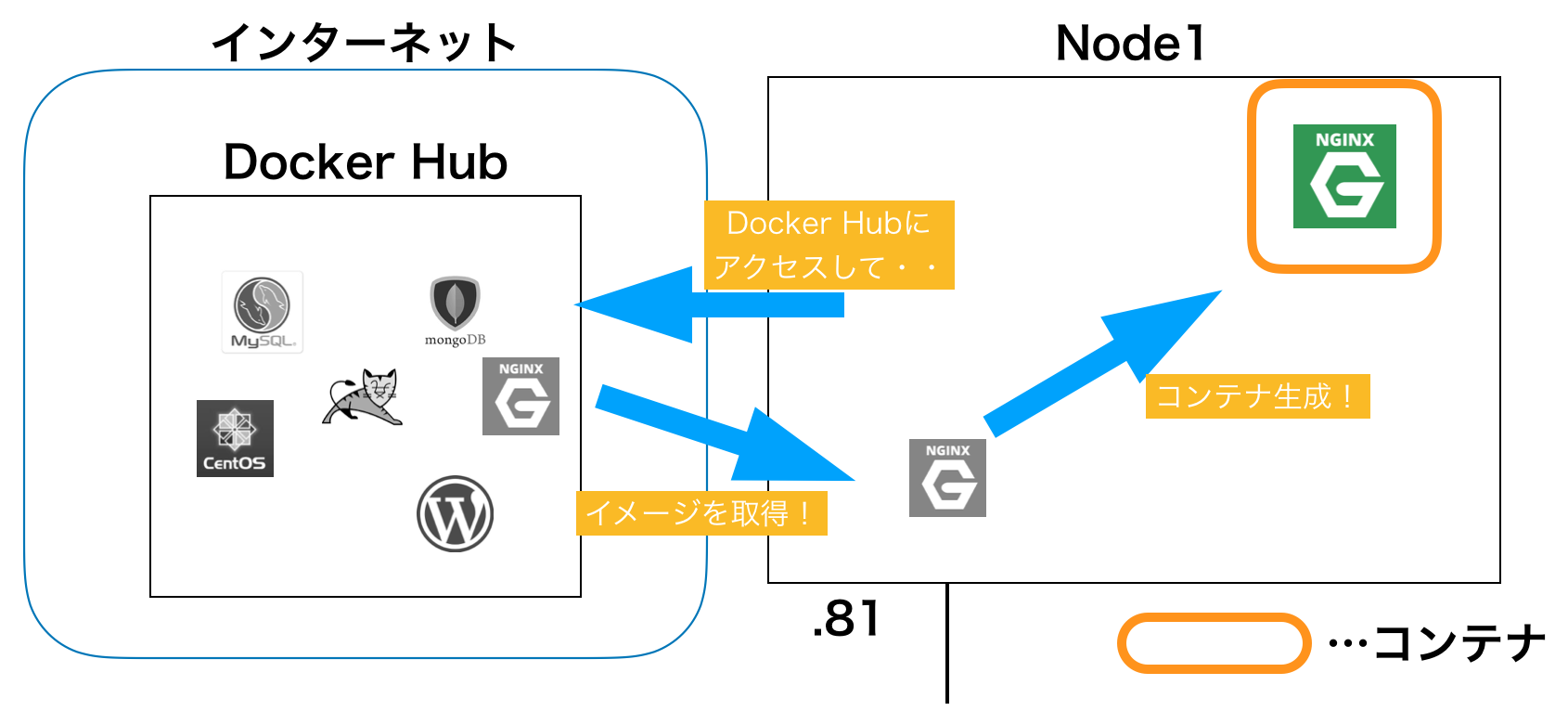
Node1の上に生成された「コンテナ」の中で、nginxが自動的に起動されました。
この「コンテナの中でアプリケーションを起動する」というのが、Docker(コンテナ型)の最大の特徴です。
「コンテナ」・・・
システム仮想化の業務に携わってきた方であればイメージしやすいかもしれませんが、仮想化について触れてこなかった方にはチンプンカンプンかと。
VMwareなどのバーチャルマシンとは何が違うのか?
そもそも、仮想化って何でやるのか?
その辺を少し整理してみると、Kubernetes/Dockerで解決できる課題が見えてくるはずです。
この辺の話は「サーバ仮想化の歴史」を読み解くとわかりやすい。
サーバの仮想化の歴史
1つの物理サーバーを占有して使用
大昔は1つの物理サーバーにOSをそのままインストールして使っていました。
イメージ的にはこんな感じ。
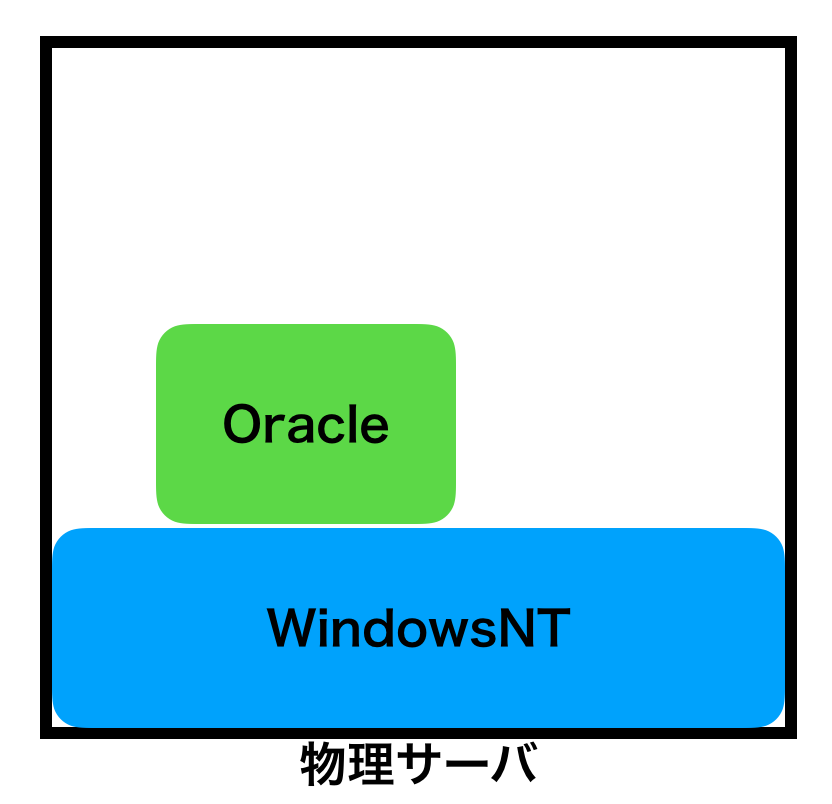
昔は物理サーバにフロッピーディスクとかCD-ROMとかが付いていて、そこにOSのインストールメディアを挿入し、物理サーバにOSを直接インストールしていました。
そして、起動したOSにDBなどの製品(ミドルウェア)を入れて、サーバとして使っていました。
この構成(サーバ占有型)で運用していると、主に以下の課題が出てきました。
- リソース(CPU・メモリ・ディスクなどなど)が勿体無い
- 初期構築に時間がかかる
- システムの移行が難しい
順番に解説していきます。
1.リソース(CPU・メモリ・ディスクなどなど)が勿体無い
例えばCPUの使用率を見てみます。
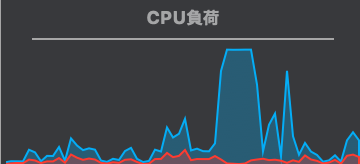
青色のグラフが、時間ごとのCPU使用率だとします。途中でCPUを100%使用しています。
でも、それ以外のところは、殆どCPUを使用していません。
このグラフ「時間毎の線」ではなく、「使用面積」として見てみてみたら、わかりやすいかと。
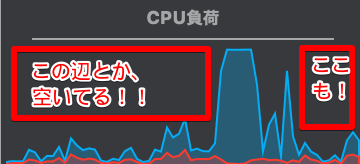
CPUとかメモリのような物理リソースは、購入にお金がかかります。はっきり言って、高いです。
なのに、上記のように未使用の面積があるって事は、それだけムダが多いって事です。
2.初期構築に時間がかかる
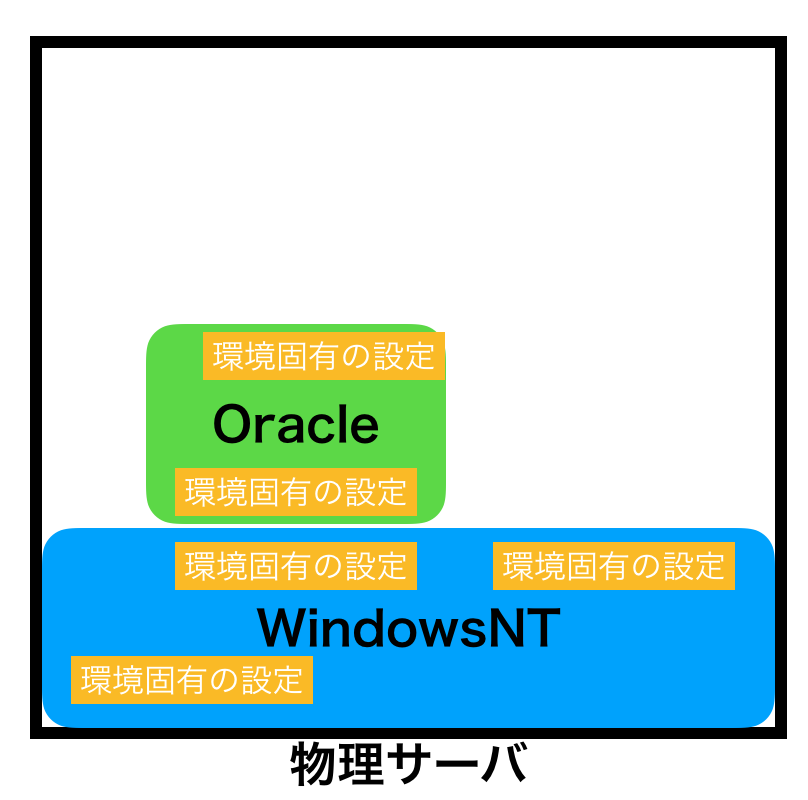
上の例ではシンプルに「WindowsNTをインストールして、Oracleをインストール」みたいに書きましたが、、
実際にはそんなにシンプルではありません。
WindowsNTの初期設定(ドメインとか、サーバー名とか、ドライバの導入とか、Windows95の時代はTCP/IPの追加導入でした)、Oracleの初期設定(ファイルを自分で作成したり、ポートの開放とか)、色々あります。
なので、実際には以下のイメージになります。

環境固有の設定をする必要があるのです。
サーバ一台の導入だったら、それ程問題になりません。
しかし、これが「100台の似たようなサーバの構築」とかだと大変です。例えば全国に支店を構えてる会社で、各拠点に同じサーバを構築する時、毎回毎回「WindowsNT入れて、Oracle入れて、細かい設定して・・・」ってやるのは、、作業量的にも人間の精神的にも大変です。
でも、昔はしていました。分厚い導入手順書を作って、現場の担当者が全ての拠点に出張して、CD-ROM片手に必死にインストールしていました。
人間がやる事なので、ミスも多発します。現場の担当者のスキルも差異があります。トラブルも多発しました。
時間もかかりました。
3.システムの移行に時間がかかる
導入当初は快適に使用できていたサーバも、使用ユーザ数が増えてくると、古くなったサーバだと対応できないことがあります。通常は数年間のユーザ増加を見込んでインフラを整備する(キャパシティ要件)のですが、それでも想定外のことが出てきます。
- 想定外の利用者増加(嬉しいこともある)
- 想定以上の年数使うことになった(予算の不足など)
- 想定外の使い方(良くない)
例えば最大100ユーザを対象にしたWebサーバを構築してたとします。初期はサクサク動いていたのですが、徐々に利用者が増えて、1000ユーザが使用した場合、サーバの応答が非常に遅くなったりします。
あと、DBサーバなどでよくある例としては、新任の開発者が何も考えずに全レコード検索のロジックを入れてしまって負荷が急増したり・・・
という訳で、CPU・メモリを最新のサーバにシステムを入れ替えることにしましたとします。
サーバ導入の初期と同様に、手順書を使って入れ直しでいける!
・・・みたいに簡単にはいきません。
年を重ねる毎に、運用担当者がどんどん設定を追加していって、初回の導入手順書以外のモノまで入っちゃってるからです。
通常は設定変更したら「変更管理表」とかに追加するルールを設けてるものですが、人間がやることなので忘れることもあります。
誰も知らない「罠」みたいな設定が入ってる可能性がある・・・
そんなこんなで「移行なんて怖すぎてできない」ケースに陥ります。
1つの物理サーバに複数のOSを導入(サーバ仮想化)
物理サーバを専有した場合、色んな課題があった事がおわかりになるかと。
それらを解決するために生み出されたのが「サーバ仮想化」の技術です。
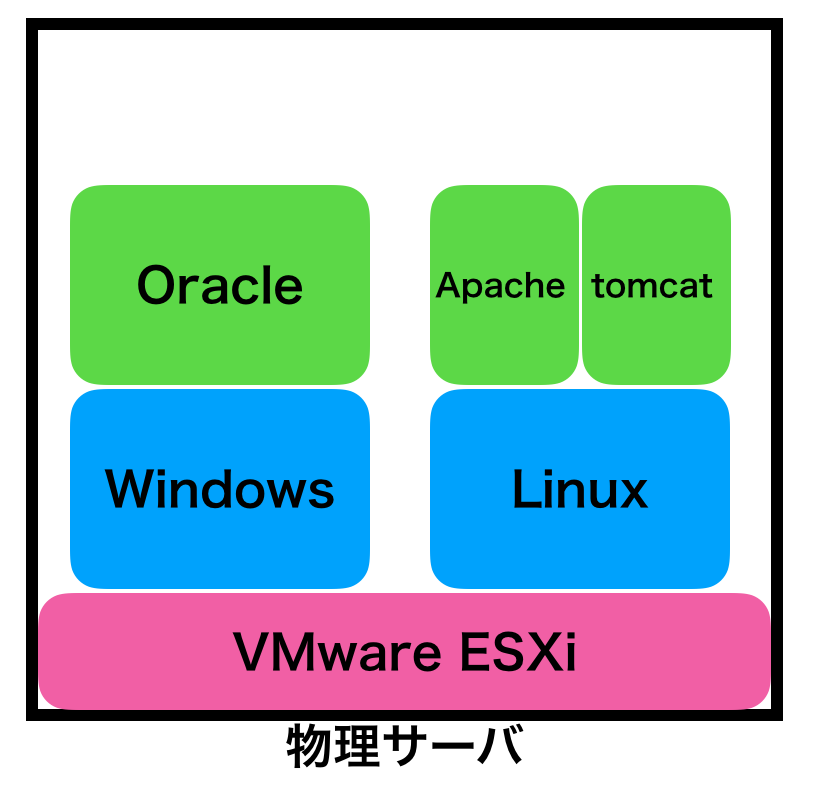
まずは物理サーバに「ハイパーバイザ」という、仮想化専用のOSを導入します(上でのVMware ESXiってやつ)。そして、その上にWindowsやLinuxを導入して「仮想的なサーバー」を作る。
(ここでは「ハイパーバイザ」と「ホストOS」の区別は割愛。コンテナ型との比較ではそれ程重要じゃないので)
ハイパーバイザの上で可動してるOSは、自分が物理サーバの中で動作していると思っています。なので、上の図で例えると、Windowsにログインしたら、これまでの物理占有型とOSの視点からは何も変わりません。
サーバ仮想化技術の代表的な製品:
- VMware ESXi
- Microsoft Hyper-V
- Linux KVM
この「サーバの仮想化」技術により、「サーバ占有型」の課題が、かなり解決できました。
まず「リソースの有効利用」です。上の例だと「Windows」と「Linux」が「同じ物理CPU/メモリ」を「共有」できます。本来なら2台必要だった物理サーバを1台にできます。
単純計算して「半分のコスト」です。
実際には2台と言わず、100台の仮想サーバを1台の物理サーバに乗せたりします。単純計算して「1/100のコスト」です。
当然ながら、そんな簡単にはいきませんが、イメージ的にはこんな感じです。
(私の家では、1台のサーバ上に「30台以上の検証用の仮想サーバ」が可動しています。)
次に「システム構築時間の短縮化」が挙げられます。
仮想サーバーの場合、そのサーバの下のハイパーバイザから見ると、仮想サーバは「一つのファイル」です。
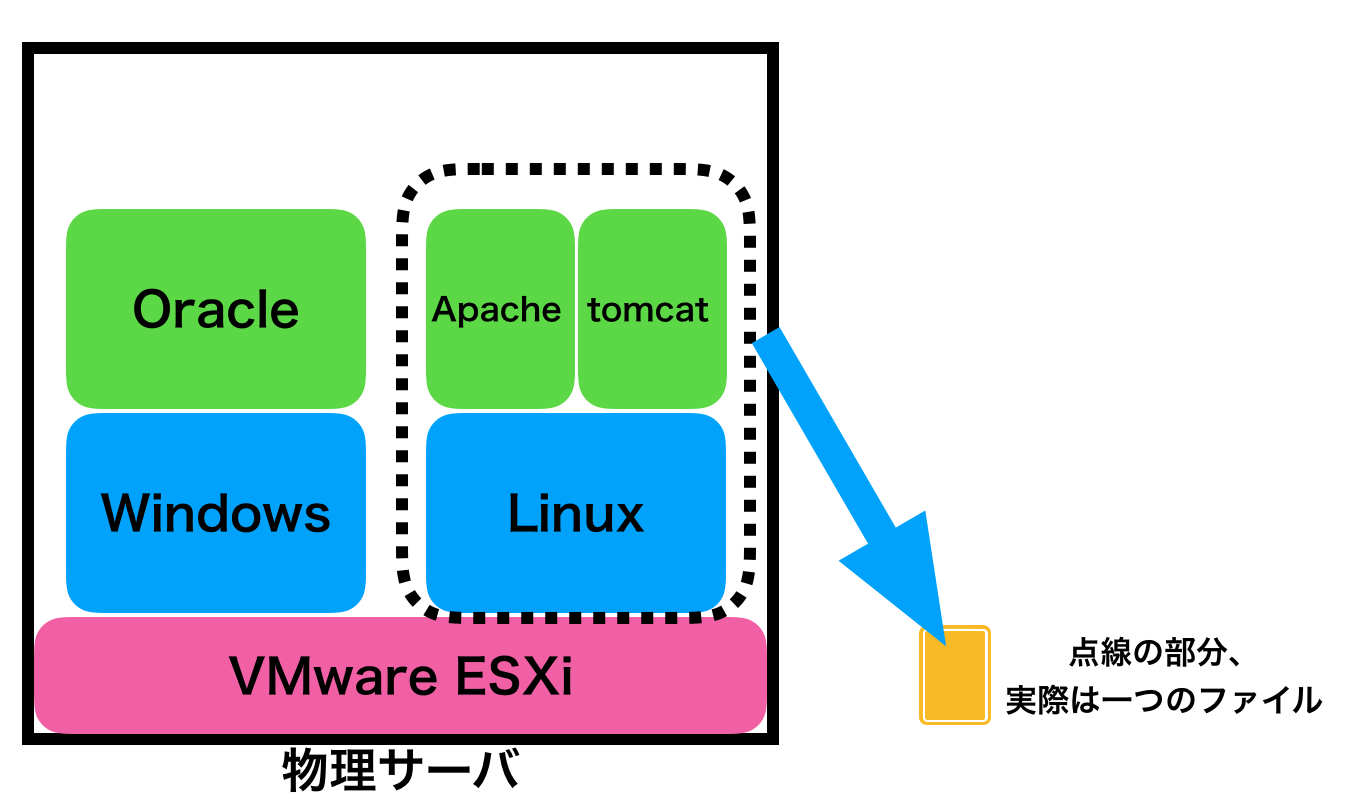
なので、他の物理サーバーのハイパーバイザ上に、このファイルをコピーするだけで、OS(とミドルウェア)の構築ができてしまいます。
これ、非常に便利です。
例えば先程の例での「全国拠点に同じシステムを導入するケース」を考えてみると、初めに導入した仮想サーバのファイルを、各拠点のハイパーバイザにコピーするだけで、初期導入が済んでしまいます。
(実際には拠点固有の設定をしたりするので、課題は残ります)
他にもこんなメリットもあります。
とある仮想サーバで、システムトラブルがあったとします。トラブルの原因を特定したい。
でも、その仮想サーバは本番で動いているので、設定を変更したくない。
手元に同じ環境があれば・・・
こんな時、でもハイパーバイザ上の仮想サーバのファイルをコピーするだけで、同じ仮想サーバを作れてしまいます。コピーした環境でゆっくり原因を特定すればよい。本番環境には影響なし。安心です。
問題解決用に準備する機材も、別に本番環境と同じ物理サーバじゃなくて良いんです。同じハイパーバイザが動けば、物理的なところは気にしなくて良い。
個人的には、この「物理的なところを、上のOSが気にしなくて良い」というのが、サーバ仮想化の最大のメリットだと感じています。
間にハイパーバイザを挟むことで、OSは物理的なモノ(物理CPUの違い、入出力デバイスの違いなど)を気にしなくてよいのです。複雑なところを「隠蔽」してるんです。
「システムの移行時間の短縮」も挙げられます。
前述の通り、上のOSは物理リソースの具体的な情報を「知りません」。これは良いことなんです。
上の例の「CPU/メモリなどのリソースが足りなくて、性能の高い物理サーバへの引っ越しが必要になった」場合、ハイパーバイザに保存されてる仮想サーバのファイルを引越し先の物理サーバ(の上に導入したハイパーバイザ)にコピーするだけで済みます。
てな感じで「サーバ占有型」よりも様々なメリットを得ることができる「サーバ仮想化」ですが、それでも慣れてくると以下の「改善されたらいいな」的な事が見えてきました。
ゲストOSのオーバーヘッド
ハイパーバイザの上に乗せるOSの事をゲストOSと呼びます。上の例だとWindowsとLinuxです。
これらは「サーバ占有型」と同じ要領で、ハイパーバイザ上にインストールします。つまり、ゲストOS毎にOSイメージを入れる「Disk使用容量の増加」が発生します。
それ以外にCPU/メモリをゲストOS毎に振り分けるオーバーヘッドなどもあります。
次回はいよいよDocker「コンテナ型」の紹介です
「物理サーバ占有型」と比べて「サーバ仮想化」は様々なメリットがある事がおわかりいただけたかと。
次回はサーバ仮想化をもう少し応用した「コンテナ型・コンテナ化」の解説をします。
コメント