
前回の記事では「サーバ占有型」と「サーバ仮想化」について解説しました。

今回は、いよいよ本質の「コンテナ型(Docker)」について紹介します。
コンテナ型について
物理サーバ占有型と比べて沢山のメリットがあった「サーバ仮想化」ですが、それでも以下の課題がありました。
- ゲストOSのオーバーヘッドがある
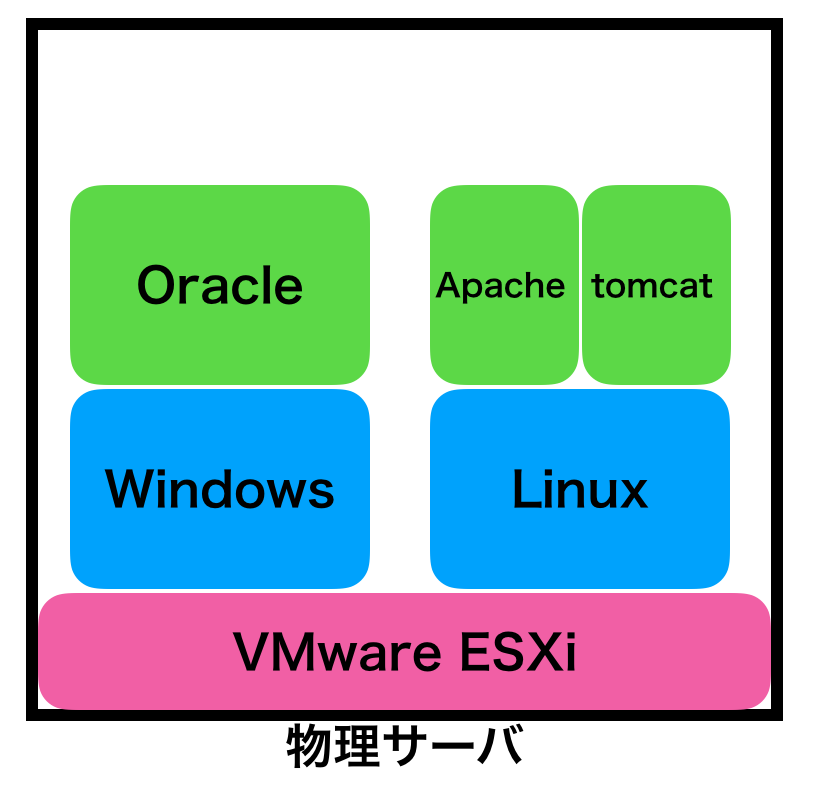
上の例だと「Windows/Linux」がゲストOSの部分です。2つOSをインストールしているので、ストレージを含む色んなリソースのオーバーヘッドがあるのも想像できるかと。
今回の「コンテナ型」は、OSのさらに上に「コンテナ」という概念の「器」を作って、その上でミドルウェア(やアプリケーション)を起動させるモノです。
上と同じ製品を入れるとなると、イメージ的にはこんな感じ(実際はDockerの箱は微妙ですが、こんなイメージで良いかと)
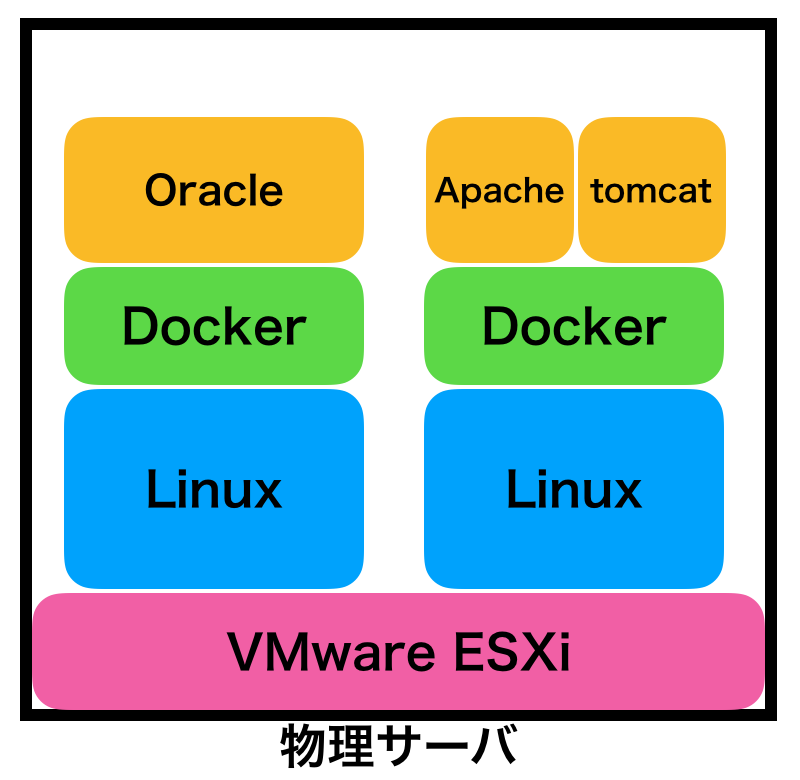
・・・逆にややこしくなってる!と感じるかもしれません。その感覚は普通です。覚える要素が増えてるからです。なので、この記事で解説しているのです。
黄色の箱がコンテナです。OSの上にもう一つ抽象レイヤーを追加したイメージです。
この一見「Dockerという箱の上にアプリが乗ったにすぎない」イメージの構成ですが、まずは特徴を見ていきましょう。
ざっくり2つあります。
OSの上の「コンテナ」でアプリが動作する
サーバ仮想化の時は「ハイパーバイザ」の上にLinuxやWindows用の仮想サーバを構築しました。ハイパーバイザの上に構築した仮想サーバは、お互いが見えていません。同じハイパーバイザ上で起動していることを意識していません。
コンテナでも同じことが言えます。例えば上記の図を例にとると、「Apacheコンテナ」と「tomcatコンテナ」は完全に分離されています。お互いが、同じLinuxの上で可動していることを知りません。
サーバ仮想化の時は「ハイパーバイザの上にOSを導入し、その上にアプリをインストール」しました。
コンテナ型の時は、「ハイパーバイザの上にOSを導入し、その上にDockerをインストールして、その上にコンテナを作る」イメージです。(実際はOSの上に直接コンテナが乗っているのですが、イメージ的にはこんな感じ)
コンテナは、ホストOSのカーネルを共有します
この辺は、Dockerの概念を理解するのみに留める場合は、細かく理解する必要はないかと思います。
OSには「カーネル」という、基本的な動作を行うためのモジュール集合体みたいなモノがありまして(入出力、ログインモジュールなど)、それらはコンテナを起動させるOS(ホストOS、上記だとLinux)の機能を使いまわしします。
誤解のないように言いますが、これは「ホストOSがCentOSだと、Ubuntuが動かない」とか言ってる訳ではありません。CentOSとかUbuntuとかは、カーネルの上に起動している「ディストリビューション」です。なので、CentOSの上にUbuntuのコンテナを起動させることも可能です。
逆に言うと、新しいカーネルの機能を使用しているコンテナは古いカーネルのホストOS上では動かない可能性もあるため、仮想サーバーのレベルの疎結合はありません。ここは気をつけないといけないポイント。でも今回の記事の本質ではない。
さて、次は(私が一番説明したかった)コンテナ化のメリットについて解説します。
コンテナ化のメリット
一見「OSの上に更にコンテナを作って、ミドルウェア(アプリ)をインストール」という、無駄に複雑になった気がするのですが、、、コンテナ化によって様々なメリットを享受する事ができます。
仮想OSに比べてリソースのオーバーヘッドが少ない
これは想像しやすいかと。
例えば、Docker Hubの最新CentOSイメージを見てみます。
[root@node1 ~]# docker pull centos:latest latest: Pulling from library/centos a02a4930cb5d: Pull complete Digest: sha256:184e5f35598e333bfa7de10d8fb1cebb5ee4df5bc0f970bf2b1e7c7345136426 Status: Downloaded newer image for centos:latest [root@node1 ~]# docker images REPOSITORY TAG IMAGE ID CREATED SIZE centos latest 1e1148e4cc2c 7 days ago 202MB 省略
わずか202MBです。安直な例ですが、CentOSのMinimumイメージよりもずっと少ないですね。
でも、実際はこのメリットよりも、以降の特徴の方がずっと大事なんです。最近はリソースも潤沢に用意することがありますし。
ゲストOSを汚さない
とても大事な特徴です。以降の全てのメリットの本質となります。
実際に使ってみれば、この特徴が一番メリットだと感じるかもしれません。
以前「サーバー占有型」の話をした時に、以下の図を紹介しました。
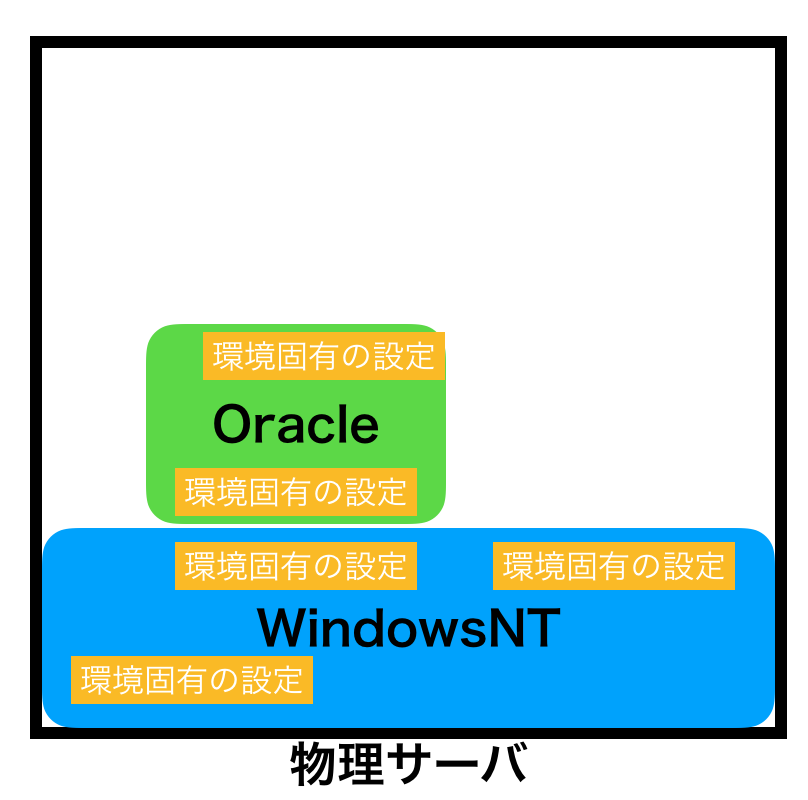
日々の運用で「環境固有の設定」が増えてきて、結果的にシステム移行の足かせになったり、運用コストの増加に繋がっていました。
これが、コンテナの場合は以下のイメージになります。
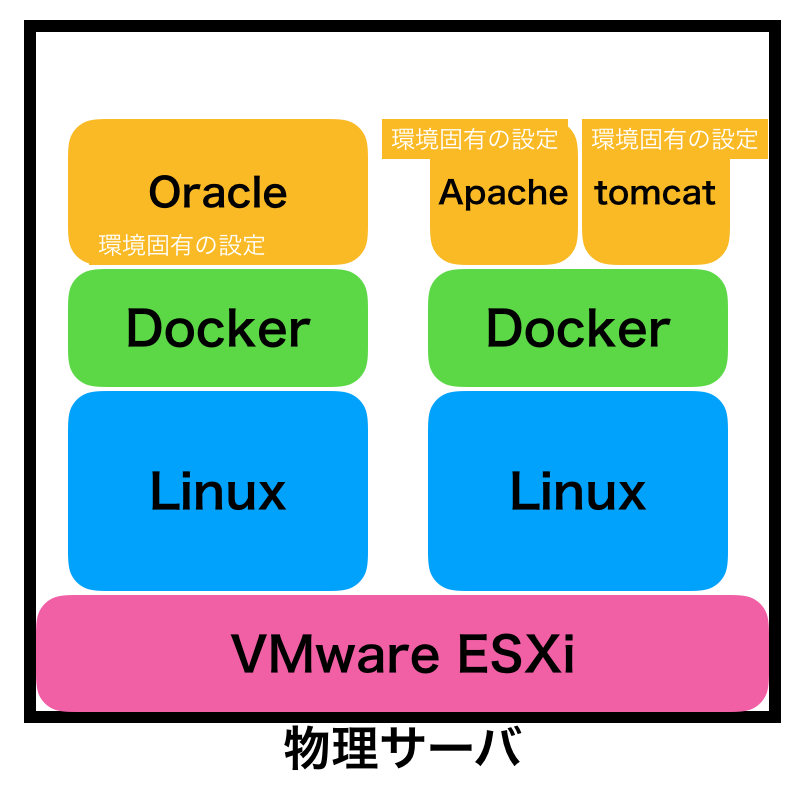
アプリケーション固有の設定は、コンテナの中で完結します(完結させるべき)。なので、OSの領域は、アプリケーションによって汚されることがありません。
最高じゃないですか!?
私は「アプリ開発者」と「インフラ構築・運用者」の両方の立場で仕事をしたことがあるので、このメリットが痛いほど理解できます。
アプリ開発者は、コンテナの中の世界に集中すれば良いわけです。
もう少し言うと、上の例では「ウェブサーバ(Apache)のコンテンツ開発者は、自分のコンテナは好き勝手やっていい」のです。Oracleやtomcatの担当者に迷惑をかけることがない。
インフラ担当者も心配事が減ります。とりあえずコンテナが動作するOS環境を整えてあげれば、後はコンテナを開発者に引き渡して「後はよろしく」ができます。
この「職務分離」が容易に出来るのは大きなメリット。今までは「やむを得ず、インフラも開発も面倒を見ていた」ってのが限定できる。各々の仕事に集中できる。
上記で「Apache担当者はOracleやtomcatの担当者に迷惑をかけることがない」と書きましたが、これは「Apache」・「Oracle」・「tomcat」で別々のコンテナを作ってる場合です。この3つを同じコンテナに入れることもできますが、これはベストプラクティスの観点から好ましくありません。上記のメリットがなくなってしまうからです。
アプリケーション(プロセス)毎にコンテナを作ったほうが、コンテナモデルのメリットを得られることができ、これはDockerの公式でも推奨されています。
ほとんどの場合、1つのコンテナの中で1つのプロセスだけ実行すべきです。アプリケーションを複数のコンテナに分離することは、水平スケールやコンテナの再利用を簡単にします。サービスとサービスに依存関係がある場合は、 コンテナのリンク を使います。
移行が容易(可搬性)
上記の特徴と本質的には同じことです。
ミドルウェア(アプリ)の設定はコンテナの中で完結します。その下のOSの世界を汚すことはありません(汚れる使い方をするべきではありません)。
つまり、Dockerさえ動作する環境であれば、他の環境で作ったコンテナが動くはずなのです。
開発環境で作ったコンテナが、本番環境に持っていくことで動作が「ほぼ」保証されている。これだけでも開発担当者はストレスが大幅に低減します。
(ネットワークのリンクなど、考慮事項は残ります)
システム拡張がラク
これも重要なポイントです。
上記の「ゲストOSを汚さない」と「移行が容易」の2つのポイントを組み合わせたメリットです。
まず、システム拡張の手法が2通りあることを押さえておきましょう。
- 垂直拡張(スケーリング)。以後は垂直スケールと呼びます
- 水平拡張(スケーリング)。以後は水平スケールと呼びます
垂直スケールとは、システムのリソースを増加させて、システムを拡張する手法です。例えば、現在Oracleが動いているVMにCPUやメモリを追加するケースが当てはまります。
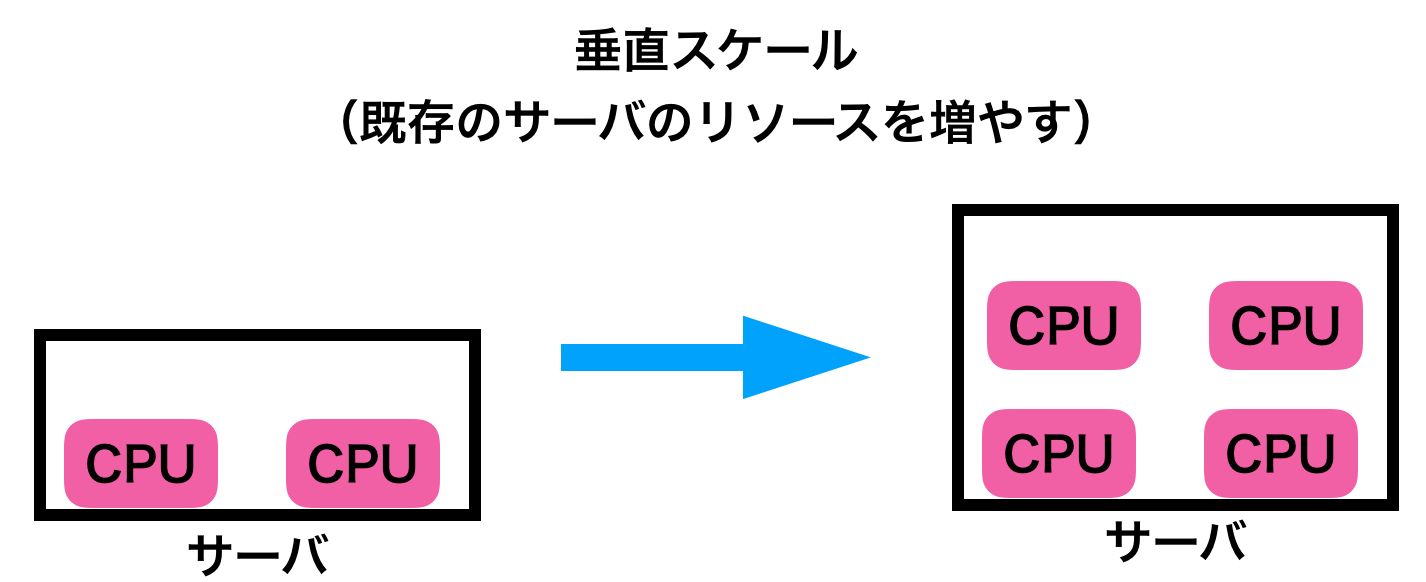
一方、水平スケールとは、複数の同一コンポーネントを追加することでスケールする手法です。例えば、1つのWebサーバで動いていた環境に、もう一つ同じWebサーバを追加するイメージ。フロントにロードバランサを置いてリクエストを分散させる。
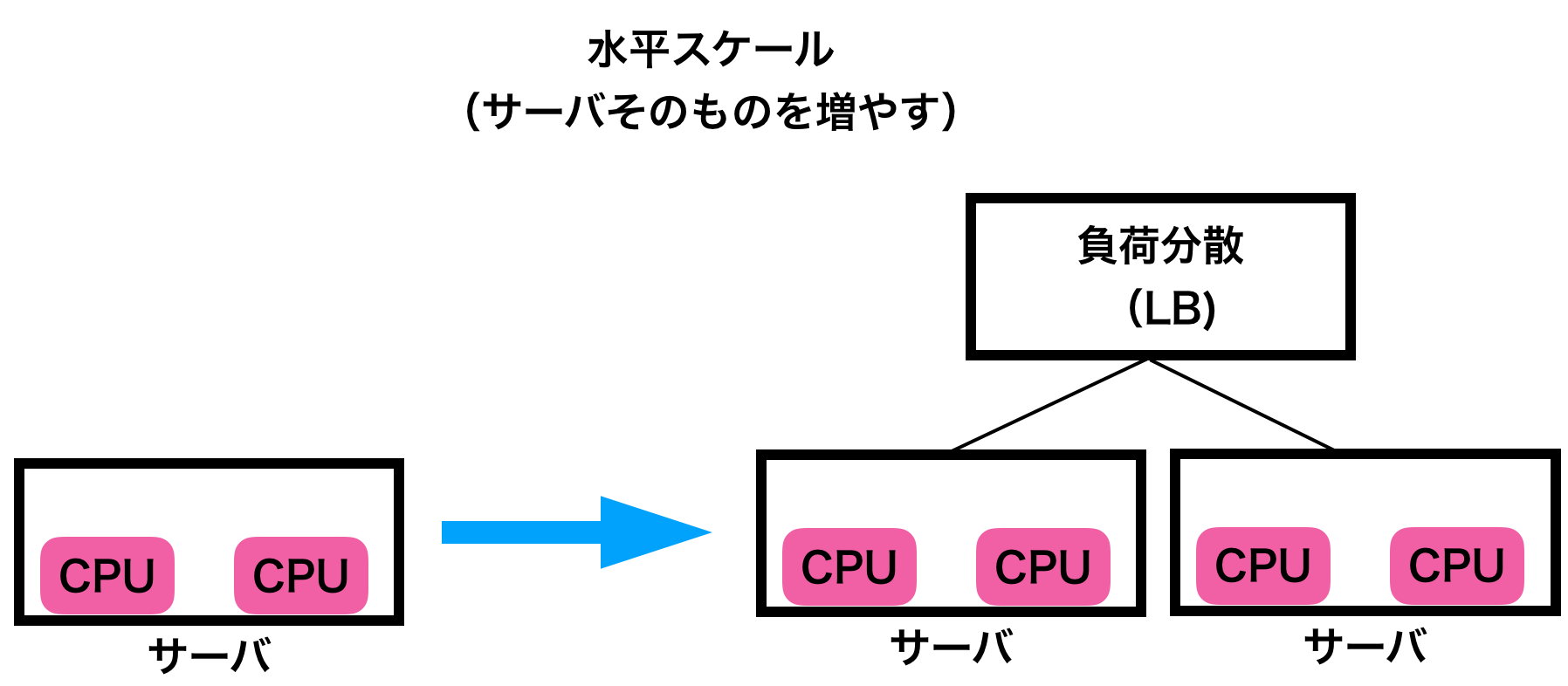
どちらが良いかは一長一短があるので「絶対こっち!」ってのはないのですが、数年前からのトレンドとしては「水平スケールの方がメリットが多い」との意見が多くなってきました(重要)。
というのも、サーバ仮想化やクラウドの普及によって「サーバ、アプリを作る」、つまり水平スケールを行う作業が簡単になってきたからです。
サーバにリソースを追加する方が一見簡単そうに見えます。でも、CPUやメモリを追加すると「アプリのチューニング」が必要になるケースが多い。例えばメモリを追加したらJavaヒープサイズを増やすとか。
一方、水平スケールの場合は、サーバなどのコンポーネントをまるごと作るので、アプリそのものに手を加える必要性が少ない(てか、水平スケールを考慮した作りのほうが簡単)。前方のロードバランサの振り分け先を追加するだけで良い。
水平スケールの場合は「可用性」もアップします(超重要)。1つダウンしても残りのサーバ(コンポーネント)で対応できる。CPU/メモリを追加しても、そのサーバがダウンしたらシステムが使用不能になる。
この2つの比較、海外では「Pets(ペット)とCattle(畜牛)」に例えられることがあります。

垂直スケーリングはPetです。一つのサーバに餌(リソース)をあげて、大事に大事に育てるイメージ。
ペットが死んだらインパクトが大きい。大事に育てた唯一の存在ですから。
一方、Cattleは沢山います。1匹の牛が死んでしまっても、残りの牛がいます。もう1匹買ってきて補填したらいいんです。
コンテナ型も水平スケールに適しています。コンテナの一つ一つを畜牛に見立てて、事前に沢山作っておき、色んな物理サーバーにばら撒いておくんです。で、負荷が増えた場合は、数を増やす。逆に負荷が下がった場合は数を減らすだけで対応できる。
この辺の話になって、ようやくKubernetesのメリットが語れるのですが、それはDockerをもう少し学んでからにしましょう。
Dockerはコンテナに全ての設定が入っています。なのでコンテナが起動してるOSと物理サーバーを意識する必要なく、コンテナを分散することが容易です。
インフラ環境のコード化が容易
これも慣れたら本当に便利です。
(コードと聞くと複雑なプログラムを想像してしまうアナタ、とりあえず読んでください)
Webサーバー(nginx)の環境を構築することを考えてみます。
- OSの初期設定(会社のポリシーに沿って、ユーザ設定やF/Wの設定など)
- yum installでnginxを導入
- systemctlで自動起動設定
- nginx.confの設定
この手の作業は一回こっきりではありません。開発環境を作った後に受け入れテスト環境、本番環境と同じものを作っていきます。
従来は「手順書」を作っていました。入力するコマンドなどを詳細に記述し、誰でも同様の操作で構築できることが望ましいとされていました。(もう、敢えて「従来」という単語を使います)
でも、時代はかなり変わってきています。
全てスクリプトや設定ファイルで完結することが可能になってきています。
手順書のメリットは「可視性」です。日本語と多少のスキルがある人だったら、それなりに理解して手順の通りに操作することができます。
一方、デメリットは「メンテナンス性」です。設定を変えたら手順書も変える必要があります。変えるのを忘れていたら、環境の差異がでてきて問題が多発します。
手順書をメンテするのは人間なので、絶対に忘れることがあります。
そこで考えを変えて、詳細の手順書を作らずに、全てスクリプトで環境作成を自動化しよう、という思想がトレンドになってきました。
これを読んでる方、気持ちはわかります。抵抗があるのはわかります。人が作ったスクリプトなんて千差万別で解読がそもそも大変だと。
このデメリットを解決するために、「Infrastructure as a code」とか「Configuration as a code」の概念が取り上げられてきたんです。
設定記述を予め決められたルールで記述するんです。
環境の自動設定ツールは沢山ありますが、Dockerの場合は「docker-compose」という自動化ツールがあります。Docker-composeについては別の記事で紹介予定ですが、記述ファイルはこんな感じ。
version: "1"
services:
web:
build: web-server
command: copy contents /var/www
ports:
- "5000:5000"
volumes:
- ./web:/code
links:
- redis
environment:
- DATADOG_HOST=node-data
redis:
image: redis
datadog:
build: datadog
links:
- redis
- web
environment:
- DD_API_KEY=__your_datadog_api_key_here__
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- /proc/:/host/proc/:ro
- /sys/fs/cgroup:/host/sys/fs/cgroup:ro細かい内容を理解する必要はありません。
要は、上記のように「定められた記述・キーワードの意味の統一」がされていたら、スクリプトみたいな「スパゲッティーを解くような複雑さ」は存在せず、それこそ手順書を読んでるのに近くなります。
「環境と手順書の二重管理」も不要です。記述ファイルそのものが手順書であり、環境構築の素となるので。
この考え、私も初めは懐疑的でした。手順書は読みやすい、コードは人には優しくない、このような先入観を持っていましたし、このように「教えられていた」ので。
(手順書が大事だ大事だ!とインフラの人なら先人に何度も何度も教えられてきてますよね)
でも、実際に設定記述書だけのアプローチに切り替えたら、本当にラクです。手順書を作る必要がない、ラク。手順書がないので、作りたい環境の差異が発生しない、安心。
想像通り、インフラのコード化は、インフラの自動化にも貢献します。Kubernetesなんてまさに「インフラのコード化がないと成り立たない」と言っても過言ではありません。
まとめ
Dockerなどのコンテナ化技術は、OSのカーネルを共有して、ミドルウェア(アプリ)の必要な設定内容をコンテナに閉じ込めるテクニックです。
この手法を取り入れることにより、以下のメリットを受けることが可能。
- リソースの節約
- OSそのものを汚さない
- システム移行がラク
- インフラのコード化が容易
この辺の特徴を頭に入れながら、実際にDocker/Kubernetesを触ってみると、「どんな課題が解決できるか?」のイメージが湧くと思います。

コメント